✨ 软件工程中的核心规律本质上反映的是人在复杂系统、时间压力和协作环境中不可避免的行为模式,这些规律决定了系统如何构建、团队如何运作以及为什么项目常常偏离预期。
原文由 Dr Milan Milanović 发布。
Original: https://newsletter.techworld-with-milan.com/p/the-20-software-engineering-laws
引言:为什么软件项目会失败,系统会腐化,团队会慢下来
大多数工程师都是用惨痛教训学会这些定律的。当你试图重写某个东西却没有交付预期结果时,或者当一个项目已经延期,再往团队里加工程师只会让它失败得更快。有时,当你开始用某个指标来衡量进度,整个团队就会开始想办法操纵这个指标。然后,六个月后,有人提到一条 1975 年的定律,恰好解释了发生的一切。
我也为此付出过代价:我花了半个职业生涯,用艰难的方式学会这些经验,很多人可能也一样。
下面列出的二十条定律,是我最常引用的那些,当然还有更多(后面会讲到)。软件开发定律解释了正在发生什么、即将发生什么,以及无论你多努力都行不通的是什么。其中一些定律已经有六十年历史。它们在 2026 年的软件开发中依然适用,在 2036 年也仍会适用,因为它们本质上并不是关于软件的,而是关于人们如何在时间压力下协作构建事物(基本上,其中很多只是人性的定律)。
这些定律不是告诉你该怎么做的规则。它们告诉你已经在发生什么,但最终仍然需要你来做决定。这些定律只是帮助你理解现状。
这些定律之所以能进入这个列表,是因为我亲眼见过它们发生在自己身上。我的书涵盖了全部五十六条定律。如果你只来得及记住二十条软件开发定律,我认为这些就是最重要的。
具体来说,我们会讨论以下定律:
- Gall 定律:一个能够正常工作的复杂系统,总是从一个先前能够正常工作的简单系统演化而来。
- KISS:保持简单。除此之外的一切都是额外负担。
- Conway 定律:组织设计出的系统,会映射其沟通结构。
- Hyrum 定律:只要用户足够多,你 API 的每一个可观察行为都会变成某个人的依赖,无论契约怎么写。
- CAP 定理:分布式系统只能在一致性、可用性和分区容错性三者中保证其中两个。
- Zawinski 定律:每个程序都会不断膨胀,直到它能阅读邮件。不能做到这一点的程序,会被能做到的程序取代。
- Brooks 定律:向一个已经延期的软件项目增加人手,只会让它更晚完成。
- Ringelmann 效应:团队规模越大,个人产出越低。
- Price 定律:一半的工作由人数平方根那么多的人完成。
- Dunning-Kruger 效应:你对某件事知道得越少,往往越自信。
- Hofstadter 定律:事情总是比你预期的更久,即使你已经考虑了 Hofstadter 定律。
- Parkinson 定律:工作会膨胀,直到填满可用的时间。
- Goodhart 定律:当一个衡量指标变成目标时,它就不再是一个好的衡量指标。
- Gilb 定律:任何你需要量化的东西,都可以用某种比完全不测量更好的方式来测量。
- Knuth 优化原则:过早优化是万恶之源。
- Amdahl 定律:并行带来的加速受限于顺序执行的部分。
- Murphy 定律:凡是可能出错的,都会出错。
- Postel 定律:发送时要保守,接收时要宽容。
- Sturgeon 定律:任何事物中 90% 都是糟粕。
- Cunningham 定律:在网上获得正确答案最快的方法,是发布一个错误答案。
那么,让我们开始吧。
想了解更多?《软件工程定律》一书 📔 已经出版。
系统是如何构建出来的
1. Gall 定律
一个能够正常工作的复杂系统,总是从一个先前能够正常工作的简单系统演化而来。
系统在现实生活中的运行效果,通常不会像纸面设计那样好,因为许多问题只有在进入真实世界后才会暴露。这些问题只有当真实用户开始使用系统时才会出现,而到了那时,系统要么能工作,要么不能。每一个能够正常工作的复杂系统,都是一步一步演化成这样的。那些一开始就试图做到完美的系统,通常都会失败。
这就是为什么大多数从零重写的新版本系统都不会成功:团队保留了之前拥有的所有功能,却丢掉了让旧系统好用的那些简单特质。
示例: 以 Instagram 为例。最初,它其实是别的东西,并不是一个图片分享平台。这个应用叫 Burbn,里面把签到、游戏、照片分享全都塞在一起。后来,创始人砍掉了除照片分享之外的一切,这个精简后的核心就成了真正的产品。
Google Wave 则走向了相反方向。它一推出就同时包含聊天、电子邮件、论坛和文档编辑器。没人能说清楚它到底是做什么的,于是 15 个月后它就死掉了。
2. KISS (Keep It Simple, Stupid)
保持简单。除此之外的一切都是额外负担。
KISS 原则提醒我们,简单性应该是我们的核心目标。如果你可以用一个 50 行脚本解决问题,而不是使用一个复杂的 500 行方案,那么 KISS 会偏向更简单的方案,因为每一行代码都有可能引入错误。
为什么简单性如此重要?软件总体上构建起来很复杂,而且必须由人来理解。简单的设计更容易维护:新团队成员能更快上手,Bug 更容易定位,修改造成的连锁影响也更少。
KISS 原则鼓励开发者抵制那种一次做太多事的“聪明”代码,也避免为了应对未来问题而设计出让当前复杂度上升的架构方案。
示例: 假设有一家创业公司需要一个功能开关系统,并决定构建一个自定义方案。他们把它做成了一个独立的微服务,拥有自己的数据库、缓存、管理界面、WebSocket 通知和 A/B 测试支持。这引入了大量复杂性,也花了很多时间构建;一旦出问题,就会造成很多麻烦。
他们真正需要的只是一个 JSON 配置文件。这本来一个下午就能完成。

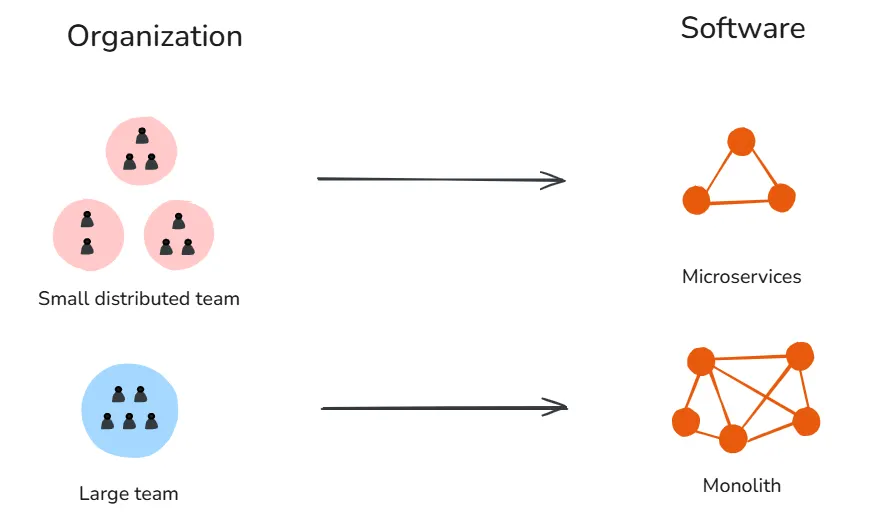
3. Conway 定律
组织设计出的系统,会映射其沟通结构。
你的应用架构其实已经被定义好了,而且本质上与你的组织结构图相同。比如,如果有四个团队一起做一个项目,你最终很可能会得到一个由四个部分组成的应用。如果负责前端、后端和数据的团队彼此不沟通,你的应用就会有三个无法良好协作的部分。
如果你在不改变公司组织方式的情况下重写系统,你得到的仍然是同一个系统,只不过换了一种语言来写。
反过来也成立。你可以先选择想要的架构,然后创建自然会产出这种系统的团队。Amazon 在 2000 年代就这么做过。他们把系统拆成由小团队管理的小型服务,这改变了系统与公司的协作方式。这被称为“逆 Conway 操作”。
示例: 许多现代 AI 组织经常把研究团队与应用工程团队分开。于是,研究团队优化基准测试,而产品团队面向真实用户发布应用。最终产出的是一个分数很好看的模型,以及一个并不好用的产品,因为双方都在围绕自己的沟通边界进行优化。
这种模式在小规模团队中也会出现。一个三人团队几乎总是会交付一个单体应用,因为把它拆开的成本高于让它保持在一起的成本。
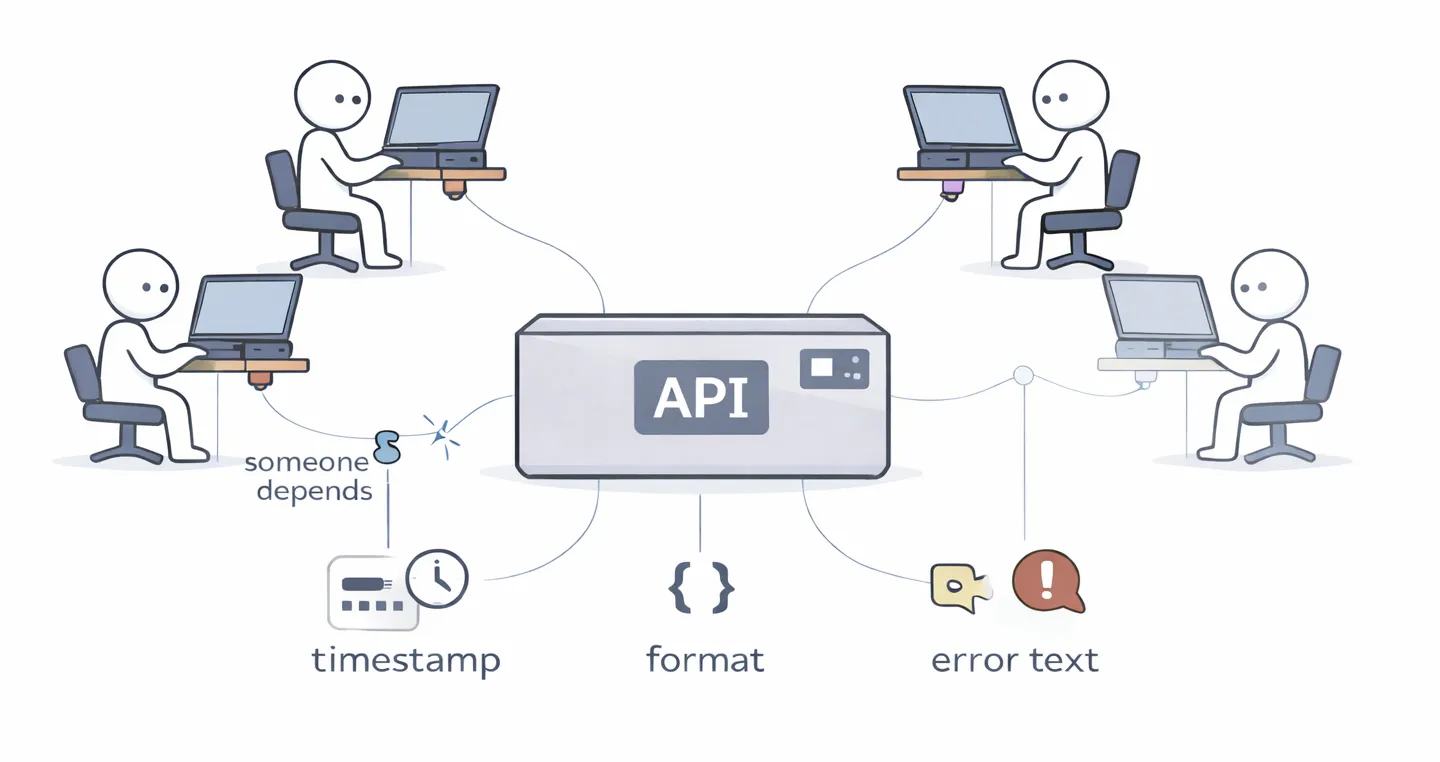
4. Hyrum 定律
只要用户足够多,你 API 的每一个可观察行为都会变成某个人的依赖,无论契约怎么写。
你写下的接口契约并不是真正的契约。真正的契约是你的系统实际做了什么,包括那些你从未预料到会重要的部分。例如,它可能是时序、错误消息文本、JSON 响应中的键顺序,以及哈希的精确字节。总有人在某个地方依赖着这一切。
这就是为什么成熟系统中的向后兼容成本如此之高。这意味着你实际维护的并不是你设计的 API,而是那个偶然形成的 API。
示例: 一个很好的例子是 SimCity 游戏。我清楚地记得它有一个 use-after-free Bug,在 Windows 3.x 上运行没问题,因为内存实际上从未被回收。后来 Windows 95 开始回收这块内存,SimCity 就崩溃了。Microsoft 在 Windows 95 中加入了一个特殊的内存分配器模式,只在 SimCity 运行时启用,这样这个 Bug 就能继续“正常工作”。
浏览器在互联网规模上也会这样做。Web 开发者构建进平台的每一个怪癖,实际上都会成为平台的一部分。浏览器无法改变这些怪癖,否则会破坏半个 Web。
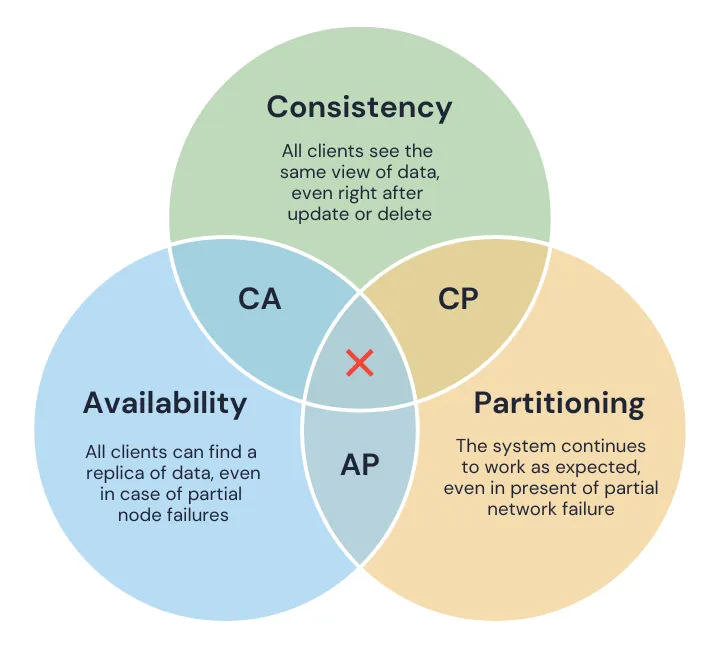
5. CAP 定理
分布式系统只能在以下三者中保证其中两个:一致性、可用性和分区容错性。
网络会失败。在分布式系统中,这不是你能绕开设计的问题,而是你必须接受的事实。一旦发生网络分区,你就必须选择:阻塞写入以保持数据一致,或者继续提供流量服务并允许副本产生偏差。每个分布式数据库都会做这个选择。大多数只是不会告诉你它选择了哪一个。它们藏在“最终一致性”或“高可用”这样的标签背后,直到事故发生时才让你发现真相。
示例: MongoDB 偏向一致性,这意味着当发生分区问题时,一些 MongoDB 副本不会接受任何数据,直到整个系统重新正常工作。另一方面,Cassandra 即使在副本之间不一致时也会继续响应查询,并在之后修复不一致。MongoDB 和 Cassandra 都没有错。它们只是针对你的系统能承受失去什么,做出了不同选择。
6. Zawinski 定律
每个程序都会不断膨胀,直到它能阅读邮件。不能做到这一点的程序,会被能做到的程序取代。
功能蔓延并不是过程中偶然发生的事情。它其实就是这个过程本身。当一个工具擅长它所做的事情,并且人们喜欢它时,人们就会一直使用它。负责产品的人希望让用户保持参与并留在平台上。于是这个工具开始承担与它相关的任务。久而久之,这个工具会变得非常缓慢,并拥有很多不必要的额外功能。
然后一个新的竞争者会带着更简单、能完成同样事情的版本出现。随着这个应用越来越受欢迎,越来越多不必要的功能又会被加进去。
示例: 一个著名例子是 Netscape,它一开始是浏览器,最后变成了包含电子邮件、新闻和网页编辑器的套件。Firefox 作为修正方案出现,把它精简下来,变得流行,但后来又加入了插件和开发者工具链。
我们也记得 Slack,它最初是为了消灭电子邮件而推出的,如今却有语音、视频、机器人和应用目录。如果产品没有正确的北极星指标,这一切都会发生。

团队是如何失去速度的
7. Brooks 定律
向一个已经延期的软件项目增加人手,只会让它更晚完成。
软件工作并不容易在团队成员之间拆分。当你把一个新人带进项目时,他需要一段时间才能上手,这意味着有经验的人必须停下手头的工作来帮助新人学习。如果你的项目已经落后于计划,增加更多人并不会让它变快,只会让情况更糟。
Frederick P. Brooks 说得很好:不能因为有九个女人怀孕,就能在一个月内生出一个孩子。软件工作也是如此。软件工作不会仅仅因为有人在做,就变得更快完成。
示例: 有一次,我是一个八人团队的负责人,我们总是落后于计划。我的第一反应是再招两名工程师来帮助我们赶上进度。但与此同时,在我们寻找新人时,有两个人离开了团队。结果看起来一切反而更好了,沟通更容易,我们完成的事情也比以前更多。所以很明显,解决办法是让团队变小,而不是变大。
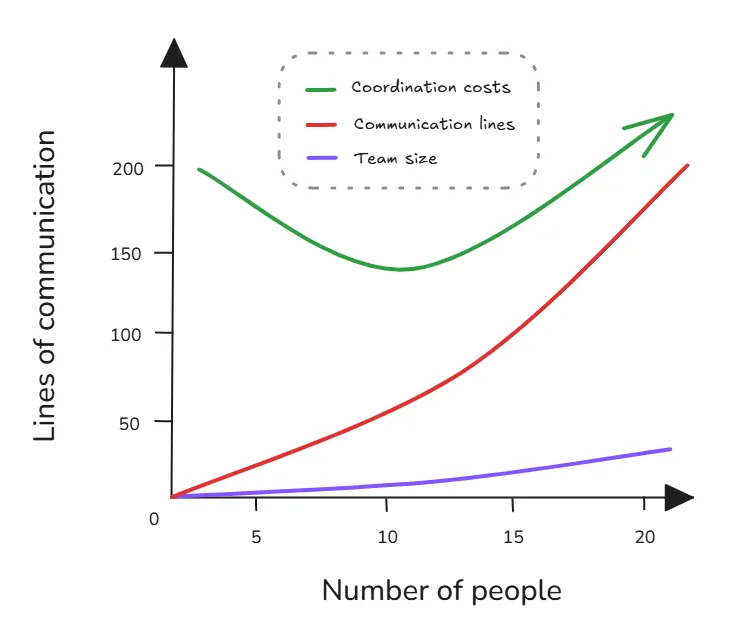
8. Ringelmann 效应
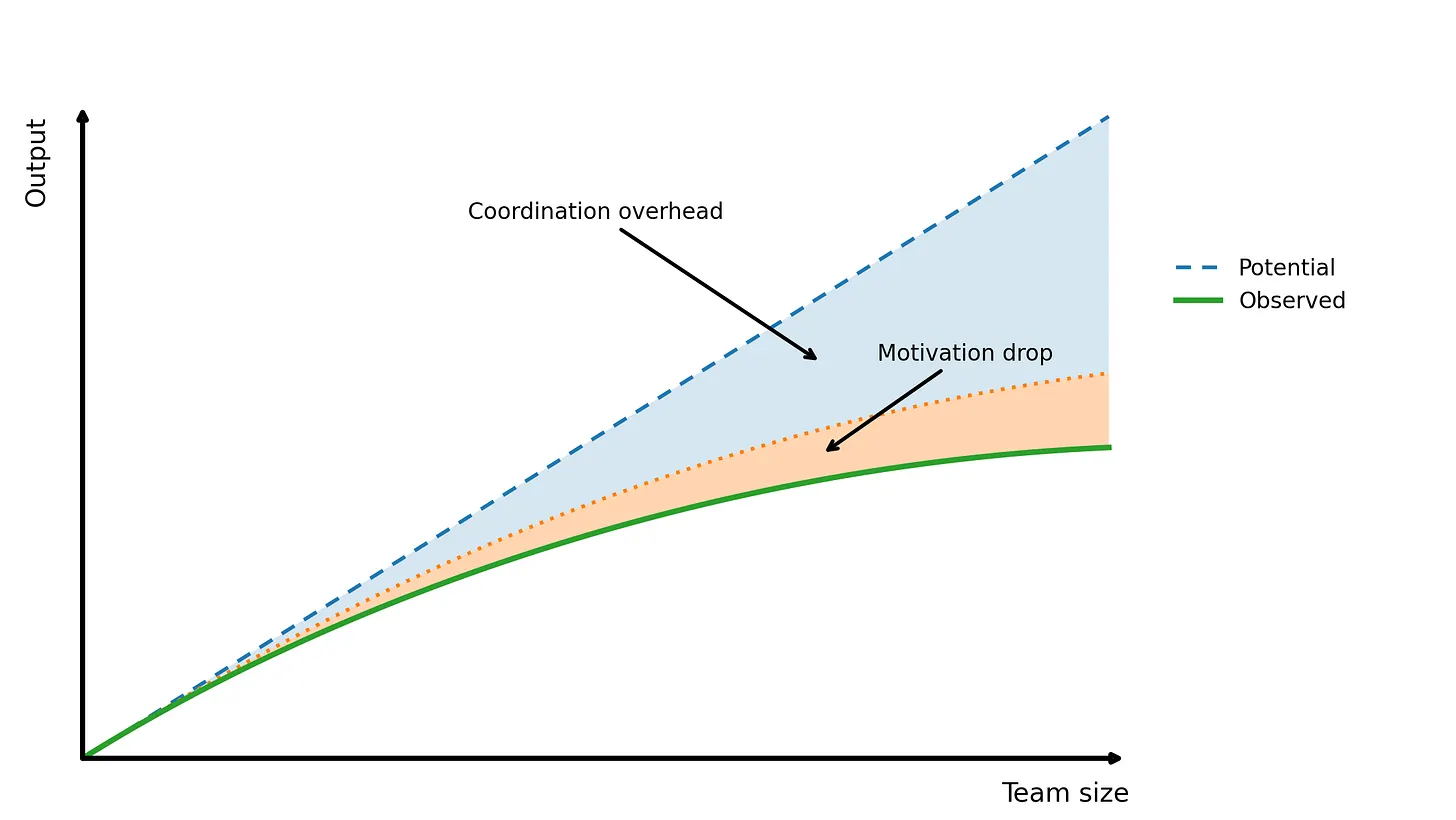
随着团队变大,人均产出会下降。
当很多人一起拉绳子时,每个人都不会拉得那么用力。一部分原因是很难顺畅协作,另一部分原因是人们会认为别人会完成那部分工作。不管怎样,这种模式是真实存在的,而且比大多数人想象得更明显。
示例: 一项大型 GitHub 研究 直接测量了这一点。2 到 5 人团队中的开发者,平均每月编写约 1,850 行代码;而 10 人团队下降到 1,200 行。到 50 人或更多时,则是 450 行。人均产出下降了 75%。
这就是为什么小团队比大团队交付更快,也解释了为什么 Amazon 的“两块披萨规则”仍然成立。它是在防御 Ringelmann 效应。尤其是在今天这个 AI 驱动的世界里,这一点更加明显,因为 AI 正在提高个人和团队生产力,高产团队的人数比以前更少。
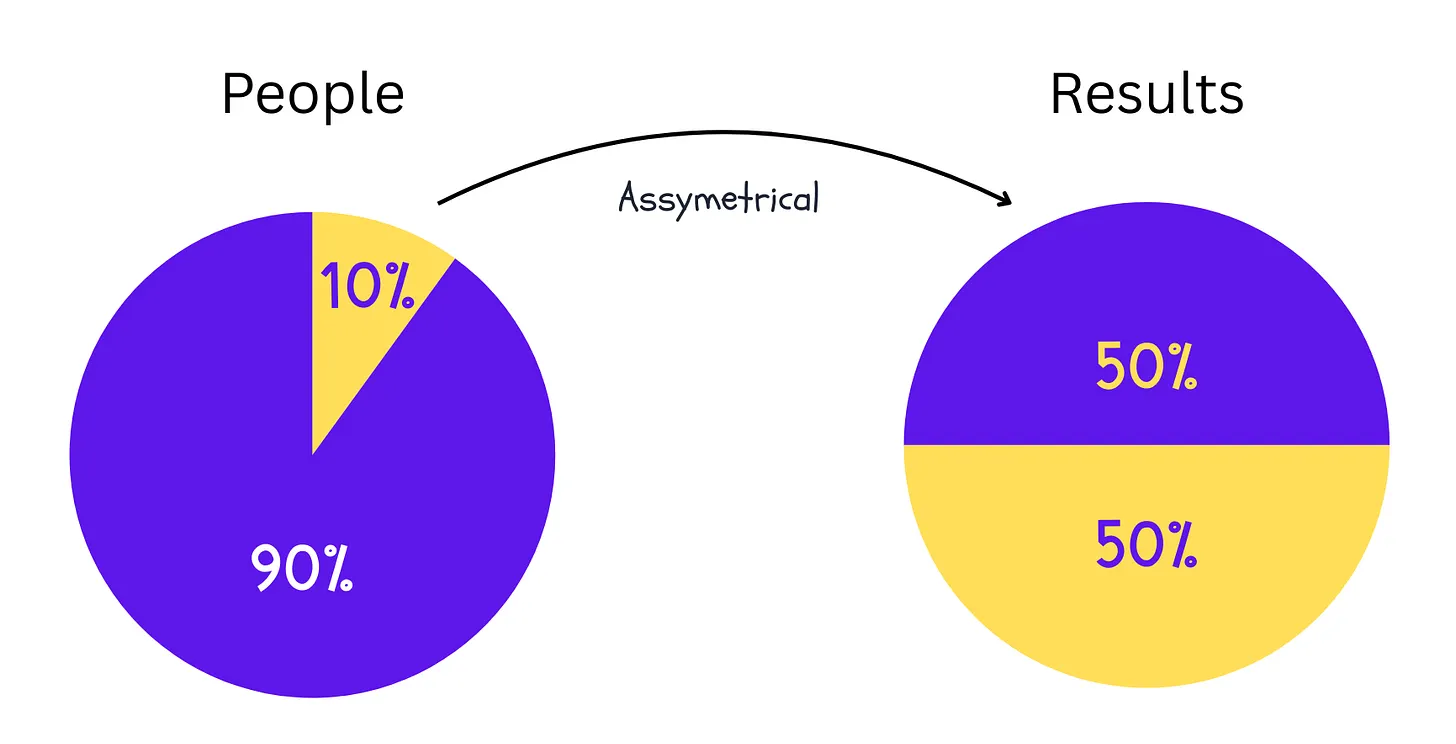
9. Price 定律
一半的工作由人数平方根那么多的人完成。
在一个 100 人的群体中,大约 10 个人真正完成了一半重要的工作。如果你有一个 16 人的群体,很可能是 4 个人完成了大部分工作。这适用于每一个创造性领域。
群体中完成大部分工作的人非常重要,但其他人也很重要,因为他们会做那些支持所有人所必需的工作。他们确保一切正常运转(有时称为胶水工作)。所以我们需要这两类人,但问题在于,如果你团队中的顶尖人员离开,团队完成事情的能力会大幅下降。
示例: 我们都知道,当 Musk 接管 Twitter 时,公司裁掉了大约 50% 的员工,而网站仍然继续运行。Price 定律预测到了这一点。但这条定律没有预测到的是,裁员带走了什么:信任与安全方面的深度、SRE 覆盖,以及事故响应能力。顶尖员工让系统继续运转。组织却失去了处理下一个难题的能力,后来 Twitter 悄悄请一些被裁员工回来。
计划为什么会漂移
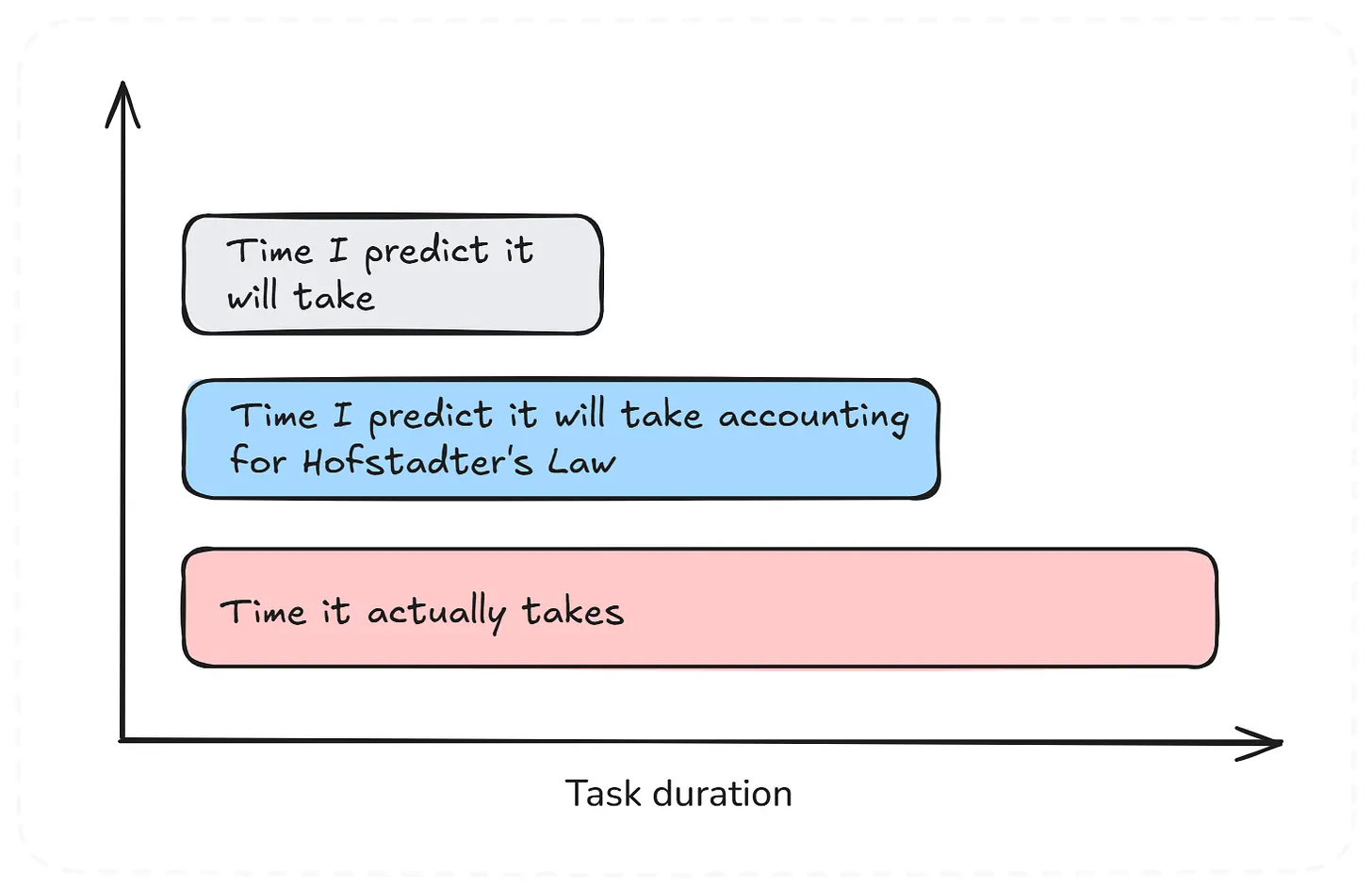
10. Hofstadter 定律
事情总是比你预期的更久,即使你已经考虑了 Hofstadter 定律。
假设你需要估算某件事要花多久。你认为四周是一个估算值,但随后你想起自己的估计通常过于乐观,所以为了保险起见,把它翻倍到八周。但最终,它花了十六周。
现在你想,下一次你会做得更好,对吧?你认为它会花十六周,因为上次就是这样。不,它这次会花三十二周,因为你不知道的事情会让你意外。这些事情包括计划外的集成问题或需求变更。
在实践中,Hofstadter 定律解释了为什么估算加缓冲、意识到 Parkinson 定律,以及使用历史数据等技术都很必要,但意外仍然会发生。
示例: Hofstadter 定律的一个好例子是 Berlin Brandenburg Airport 项目。软件集成过程比预期花费了长得多的时间,因为它涉及 75,000 个传感器和 50,000 个照明装置。原计划用 18 个月完成,但后来他们意识到这不可能,于是把时间线延长到 30 个月。最终,它花了 7 年才完成,最终成本达到 70 亿欧元,比计划高出 2.5 倍,机场晚开通了 9 年。
11. Dunning-Kruger 效应
你对某件事知道得越少,往往越自信。
令人不舒服的部分在这里。你完成某件事所需要的技能,和你判断自己完成得好不好所需要的技能,是同一种技能,而这正是问题所在。不太擅长某件事的人看不到自己哪里做错了,所以会以为自己比实际更擅长。而真正擅长的人能看到自己仍然做错的所有地方,所以会以为自己没有实际那么擅长。
示例: 当被问到某件事什么时候能完成时,新开发者经常给出自信而精确的估计,而有经验的开发者会给出范围(也就是著名的“看情况”回答)。初级开发者并不是故意错得自信。他们只是还不知道自己不知道什么(未知的未知)。
人们通常会在一开始对新技术非常兴奋。这是因为他们还没有大量使用它。我们现在正在看到这种情况发生在 Artificial Intelligence 上。那些说 AI 什么都能做的人,通常是那些并不每天使用它的人,比如管理者。
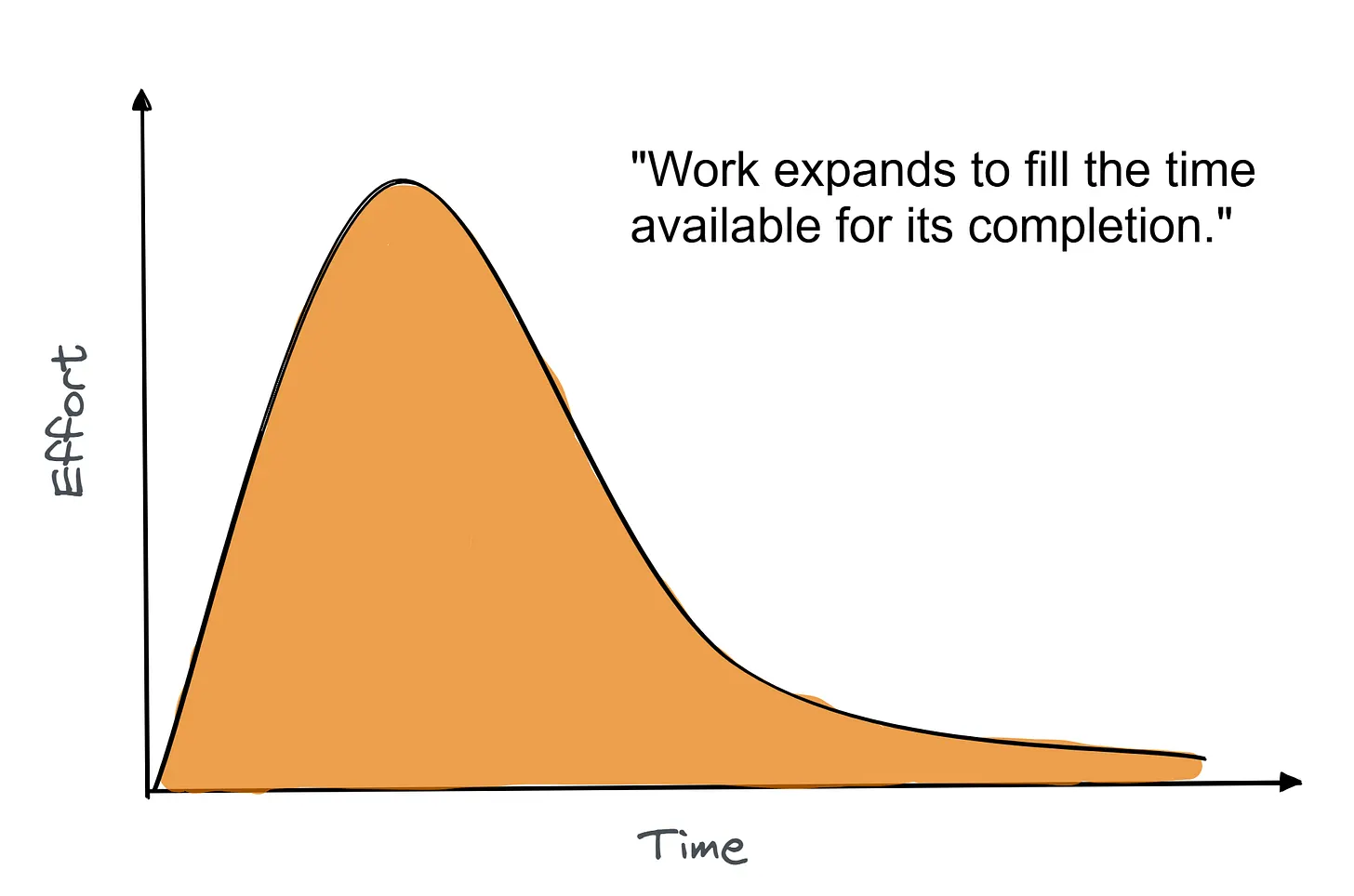
12. Parkinson 定律
工作会膨胀,直到填满可用的时间。
如果你给开发者两周时间去做一个两天就能完成的任务,它就会花两周完成。这并不意味着开发者懒惰或拖延。人们倾向于把手头拥有的时间填满。在这两周里,开发者很可能会花时间制定计划、尝试方案,并添加一些并不需要完成的额外任务(镀金)。但如果截止日期是一天内完成,它很可能当天就会完成。
Parkinson 定律的要点是,如果你给人们一定的时间去做某件事,他们很可能会用满全部时间。所以,团队应该设定清晰且现实的时间限制(也就是 deadline-driven development)。不过,管理者必须审慎使用它,把 Parkinson 的洞察与现实的排期结合起来。如果你把时间线压缩得太厉害,就可能撞上 Hofstadter 定律,它提醒我们,即使有缓冲,工作通常仍然会比预期更久。
示例: 一个开发者如果被给了两个月来完成一个一周的任务,可能会花一个月做不同方案的原型,另一周争论架构,最后三周打磨没人要求的细节。如果同一个任务被给出明确的一周截止日期,它就会在一周内交付。
指标如何扭曲工作
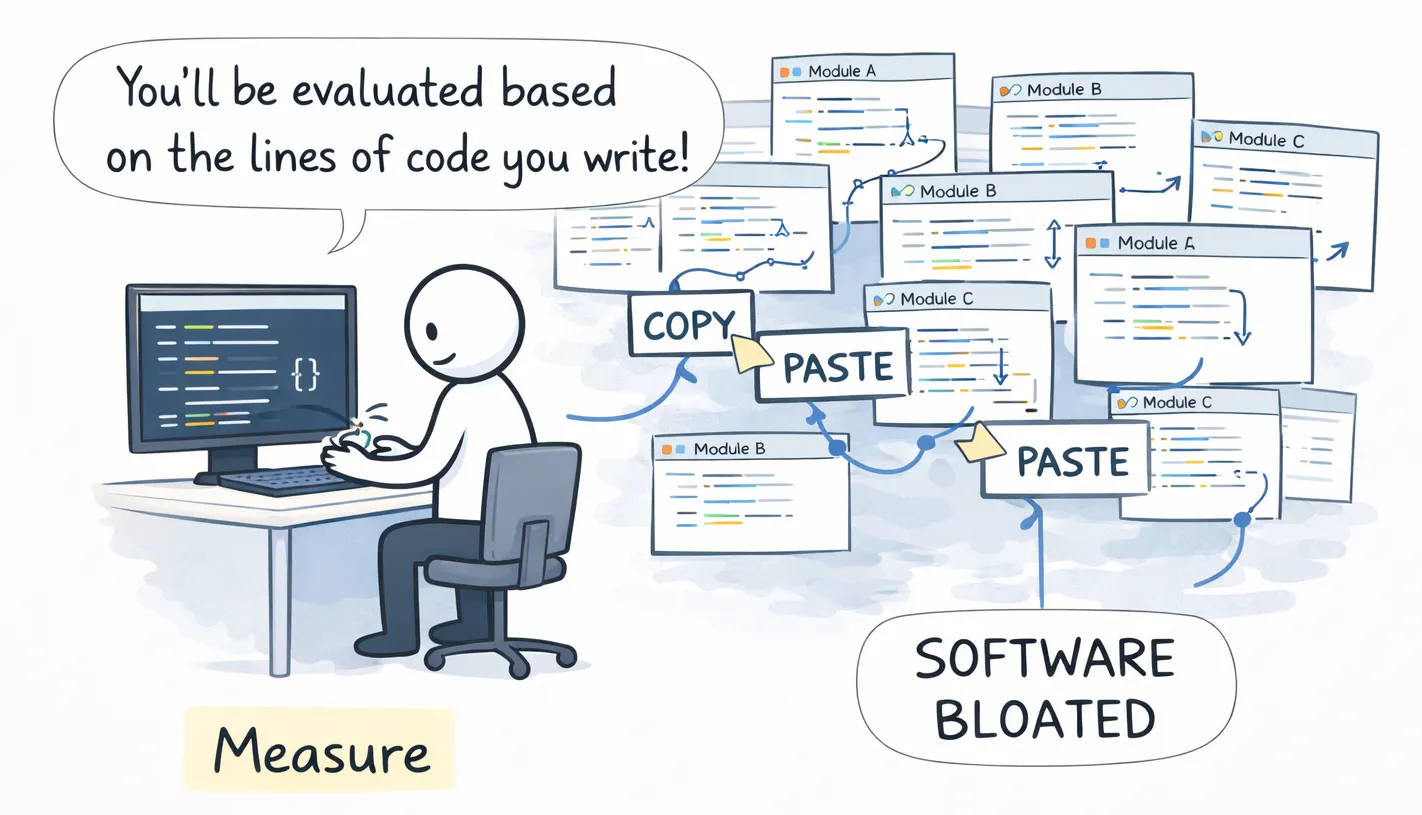
13. Goodhart 定律
当一个衡量指标变成目标时,它就不再是一个好的衡量指标。
我们可以用很多不同方式来衡量工作,例如关闭的 Bug 数量、事故数量、测试覆盖率或团队速度。当我们开始根据这些东西来衡量人的绩效时,他们就会专注于让这些数字看起来更好,而不是真正把工作做好。
数字会上升,但工作不会变得更好。这是因为当我们给人们激励时,他们会做能获得奖励的事,而不是我们真正想要的事。当我们衡量错误的东西时,人们就会为了领先而做错误的事。
示例: 我见过一个团队在 2000 年初因为编写代码行数而获得奖励,几年后又因为创建 PR 的数量而获得奖励。开发者开始复制粘贴,而不是抽取共享逻辑。有些人几乎为每一次提交都创建一个 PR。
现代版本是每位工程师消耗的 AI token 数量(称为 tokenmaxxing)。更多 token 正被当作生产力的标志。
14. Gilb 定律
任何你需要量化的东西,都可以用某种比完全不测量更好的方式来测量。
Gilb 定律就像 Goodhart 定律的另一面。看着 Goodhart 定律时,你可能会说,有指标是坏事,但这其实并不对。完全没有指标甚至更糟。如果某件事对你很重要,你就应该尝试找到一种方式来衡量它,因为我们无法改进那些不测量的东西(正如 Peter Drucker 的名言所说)。
示例: 开发者生产力通常很难衡量,而且一直如此。我们曾有许多糟糕的指标,从代码行数到 token 消耗。但部署频率和变更前置时间可以作为代理指标给你提供信号(就像 DevOps 中的 DORA 指标)。
什么会在负载下崩坏
15. Knuth 优化原则
过早优化是万恶之源。
大多数性能工作发生得太早,而且发生在错误的地方。团队优化那些永远不会成为热点的代码路径,引入并不需要的复杂性,并把时间耗在解决一个他们也许永远不会达到的规模问题上。
所以最好的方式是先写出能工作的代码,然后检查它的性能。如果有问题,工具会告诉你问题在哪里。如果没有,就继续前进。
示例: 我曾在一家创业公司工作,我们花了大量时间搭建 Kubernetes。问题在于,我们这么做是为了支撑数百万用户,而当时我们甚至还没有 10 个用户。我们在为不存在的负载准备基础设施。我们的产品功能甚至还没有完成。
我的一位同事说,在我们担心如何支撑数百万用户之前,应该先确认是否有 100 个人真正想要我们的产品。他是对的。我们最终还是延期发布了。
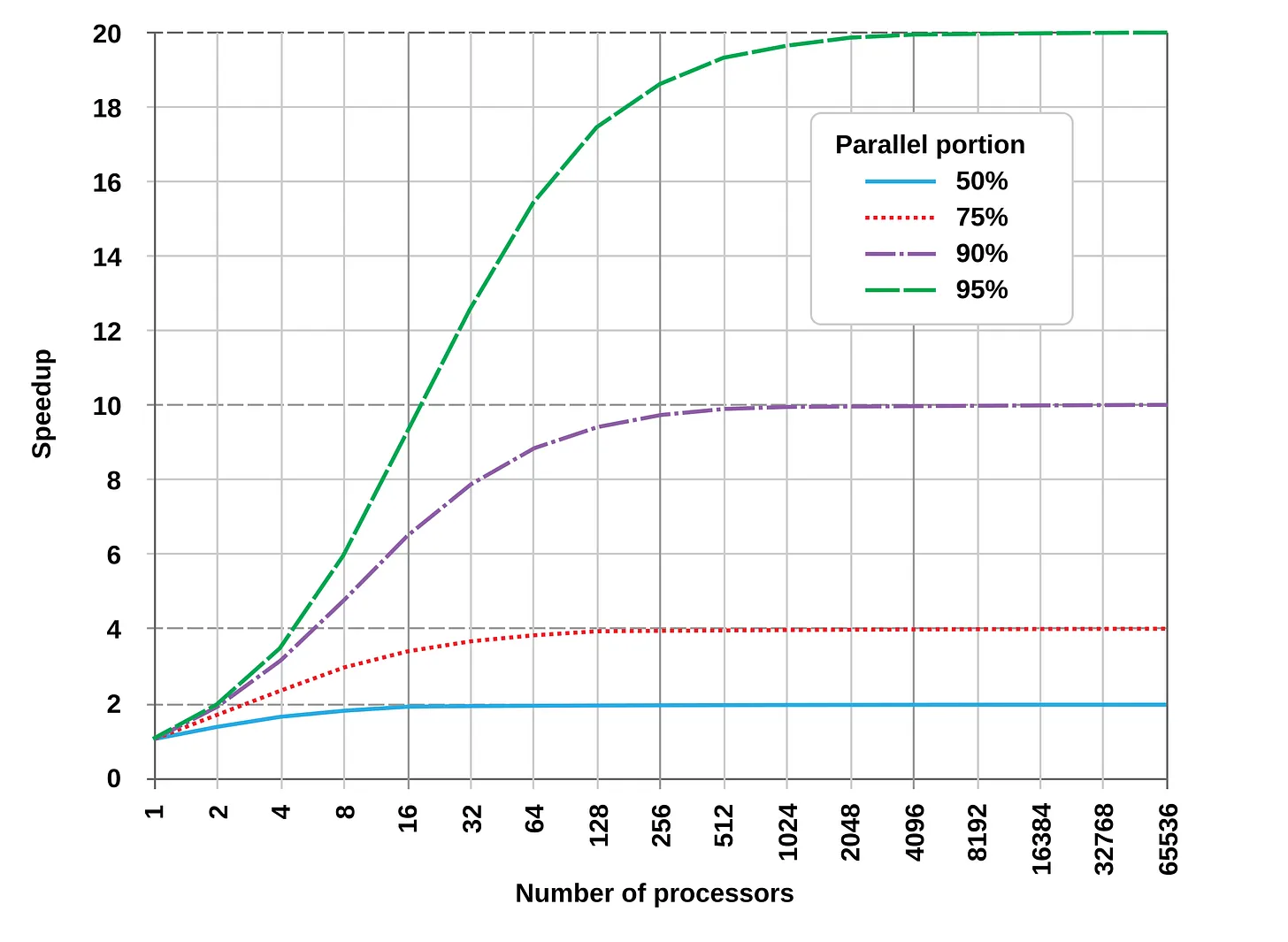
16. Amdahl 定律
并行带来的加速受限于顺序执行的部分。
如果你 10% 的工作必须顺序完成,那么无论你使用多少台计算机,整体工作最多只会快 10 倍。如果 50% 的工作必须一件一件做,那么整体最多只会快 2 倍。
同样的事情也会发生在人身上。如果有一组人必须对关于构建方式的每个决策都点头同意,那么无论你有多少工程师,这都会限制团队的工作速度。如果你增加工程师,但他们都必须等待同一组人批准,那么排队的人只会变得更长。你的工程师团队仍然会很慢,因为做决策的那组人就是瓶颈。工程师团队的工作速度,只能快到决策者那组人的速度。
示例: 通过增加更多应用服务器来扩展 Web 流量是有帮助的,直到每个请求都打到同一个共享数据库或认证服务上。此时,继续增加横向扩展就没有用了。
关于 AI 生产力的讨论现在也触到了天花板。AI 让编码更快,但你仍然必须思考、检查、修复错误,并在那些无法同时完成的步骤上协作。这限制了你最终能获得的收益。这就是为什么有些工程师看到自己的工作速度提升 10 倍,而另一些人只看到 1.2 倍提升。
17. Murphy 定律
凡是可能出错的,都会出错。
在软件中,Murphy 定律经常被用来解释 Bug 和生产事故:代码中任何可能出错的地方(空指针、竞态条件、网络中断)最终都会显现出来,尤其是在大规模用户场景下,或者在最糟糕的时间点(周五晚上)。
在实践中,这条定律鼓励开发者编写更具防御性的代码。这意味着检查空值、处理异常、验证输入,并在错误发生时优雅失败。它也提醒 DevOps 团队通过实现监控、启用回滚和维护应急计划来预判故障。
示例: 2024 年 7 月 19 日,CrowdStrike 对 Falcon Sensor 设置进行了变更。这个变更在 Windows 机器上造成了内存问题,使 850 万台 Windows 机器停止工作并显示蓝屏。为了解决这个问题,必须有人登录到每台机器并应用修复,因为那些机器无法启动。这个过程无法远程完成。而这一切发生在一个周五早晨,当时没有 IT 员工在工作。它给航空公司、医院和银行都造成了问题。那天,所有可能出错的事情都出错了,正如 Murphy 定律所说。
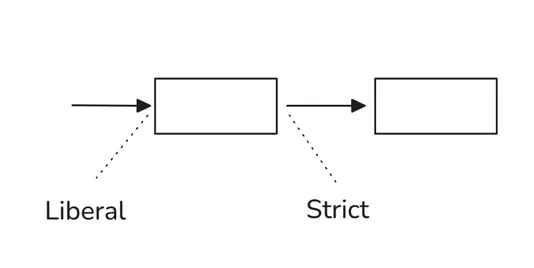
18. Postel 定律
发送时要保守,接收时要宽容。
这条定律说,如果你的服务器发送 HTTP 响应,它应该严格按照规范格式化标头。但如果你的服务器收到一个 HTTP 请求,其中标头顺序不常见或格式不寻常,只要你能安全地解释它,就应该继续处理,而不是直接断开连接。
浏览器在规模上就是这么做的。Web 上的大多数 HTML 都写得不正确,但现代浏览器仍然会渲染它们。如果浏览器很严格,半个互联网都找不到了。
但有一件事需要考虑。过于宽容是有代价的:如果每个人都接受任何东西,问题就永远不会被纠正,只会变得更加混乱。
在安全敏感的代码中,容忍输入可能会让攻击者更容易找到漏洞。所以,基本思想仍然成立。你需要运用判断力,因为宽容并不等于放任。
示例: 在 API 中,假设你的服务期望一个时间戳。如果它收到一个没有时区的时间戳,你可以不直接拒绝,而是假设它是 UTC,或者仍然尝试解析它,这就是在接收时保持宽容。但当你的服务返回数据时,你总是包含时区,以确保输出保守且精确。
如何更好地判断
19. Sturgeon 定律
任何事物中 90% 都是糟粕。
我们创造的大多数东西都不会被使用,我们写的大多数代码也并不好。我们启动的大多数项目,并不会交付我们以为它们会带来的价值。这本身并不是坏事。这就是我们试图创造新事物时的现实。如果我们假装一切都很棒,就会以同样方式对待每个项目,这会让事情变得过于复杂。
真正重要的是那些项目中的少数,比如 10%。找到这些项目,并摆脱其余项目,才是真正需要技巧的地方。
示例: WordPress 的目录中大约有 57,000 个插件。其中超过 34,000 个在过去 2 年没有更新,近 19% 的插件没有任何活跃安装。少数维护良好的插件支撑着超过 40% 的公开 Web。这种分布就是 Sturgeon 定律的一张截图。
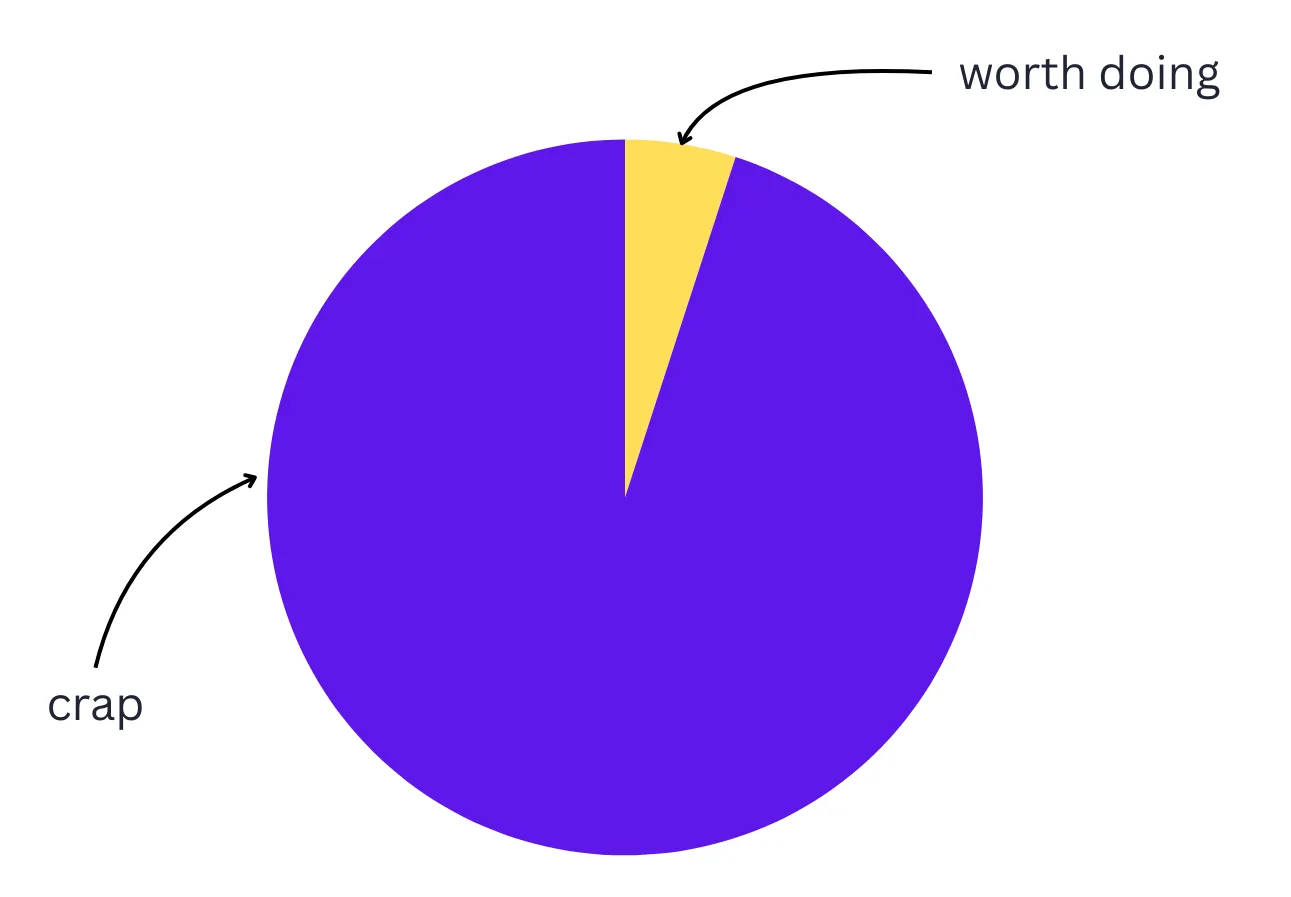
20. Cunningham 定律
在网上获得正确答案最快的方法,是发布一个错误答案。
当你在某个在线论坛上提问时,通常得不到回应。如果你发布了明显错误的内容,人们就会跳出来纠正你。他们看到一个问题时可能只是路过,但当看到错误内容时,往往忍不住要纠正。你其实可以利用这一点。如果你在某件事上遇到困难,不要问你应该怎么做。相反,提出一个你知道并不太好的方案,或者分享一个草稿,然后看看会发生什么。正确答案可能会在你甚至没有主动提问的情况下出现。
请注意,这个技巧只有在你周围的人知道自己在说什么时才有效。如果你所在的群体里,每个人都和你一样困惑,那么一个错误答案实际上可能弊大于利。在这种情况下,错误答案可能会变成人们开始相信的信息。
示例: Wiki 以及后来的 Wikipedia 的整个赌注,都是建立在这个洞察之上的。人们纠正错误的速度,比从零开始写文章更快。这个赌注在文明尺度上获得了回报。

结论
在这篇文章中,我分享了一些我在职业生涯中见过的最有影响力的定律。你不必把它们全部记住。前五六条定律就能帮助你解决大多数问题。其余定律,则是在新问题出现时派上用场。
更重要的是知道一条定律什么时候适用,什么时候不适用。这二十条定律经常相互冲突。Knuth 说不要过早优化。Amdahl 说要找到并修复项目中拖慢一切的部分。两者在某些时候都是正确的。关键在于知道现在该用哪一条。
另外,这个列表是我的列表。你的列表会不同。那些曾经给你造成问题的定律,对你而言会比那些没有造成过问题的定律更重要。随着时间推移,你会添加自己的定律。当你注意到它们时,把它们写下来。每个项目、事故或重写记录一行。哪条定律帮到了你?哪条定律给了你建议?发生了什么变化?你的个人列表会比我能给你的任何列表都更有帮助。
自从 Brooks 在 1975 年写下他的书以来,框架、平台和部署模型都已经改变了。但这些定律没有改变。它们描述的是唯一没有改变的东西:人类在尚未完全理解的约束下共同构建事物。
这就是为什么它们值得在项目出问题之前学习,而不是之后才学习。